База знаний
Обучите бота по вашей документации

Чтобы бот мог отвечать на вопросы по вашей предметной области, необходимо предоставить ему базу знаний, которая может быть представлена в виде веб-сайта, google документа, файлов, либо произвольных текстовых данных.
Чем полнее и точнее ваша база знаний, тем лучше отвечает бот.
Объём базы знаний и количество загружаемых данных ограничены лимитами. При необходимости лимит можно расширить.
База знаний статична и правится человеком. Если вместо этого нужны живые данные, которые бот сам накапливает и обновляет в процессе диалогов (жалобы, контакты клиентов, каталог товаров и т.п.), используйте Память.
Добавление веб-сайта
Для добавления веб-сайта необходимо указать адрес сайта и выбрать парсер.
Парсер по умолчанию подходит для большинства веб-сайтов. Также доступны парсеры, подходящие под конкретные платформы, такие как: Google Документы, Google Таблицы, Usedesc, Confluence, Carrot, Notion, HelpDeskEddy, Omnidesk.
Если ваша база знаний не загружается, то убедитесь, что она доступна для публичного просмотра. Например, попробуйте ее открыть в режиме инкогнито.
Можно выбрать стратегию обхода веб-сайта:
- Весь сайт - парсинг всех страниц с тем же доменом.
- Одна страница - парсинг только этой страницы.
- Папка - парсинг всех страниц, которые начинаются также, как заданный URL.
Документ Google Sheet
Документ Google Sheet должен содержать два столбца:
- первый столбец - заголовок статьи;
- второй столбец - тело статьи.
Таким образом, каждая строка документа - это как одна статья в базе знаний.
Сайты и html страницы, опубликованные google документы
Страницы разбиваются на части (фрагменты) по заголовкам h1, h2, ... Например, для такой структуры статьи:
Главный заголовок
Общие данныеподзаголовок 1
Данные 1подзаголовок 2
Данные 2
получится 3 чанка,
- title = h1, headings = [h1], content = "Общие данные"
- title = h1, headings = [h1, h2], content = "Данные 1"
- title = h1, headings = [h1, h2], content = "Данные 2"
Это важно учитывать при написании страниц, т.к. при поиске ответов Wikibot ищет фрагменты похожие на вопрос пользователя. Если фрагменты будут очень маленькие, то каждый из них не будет содержать всего ответа.
Если у вас нет Базы знаний, то самым простым вариантом обучения бота будет
создать Google документ. Опишите в нем всё, что должен знать бот. Обязательно
добавьте стили заголовков для смысловых групп. Опубликуйте документ Файл -> Поделиться -> Опубликовать в интернете. Используйте полученную ссылку для
добавления источника данных.
Использование изображений из базы знаний
Викибот может использовать изображения из вашей базы знаний, чтобы прикреплять их к своим ответам. Изображения должны быть добавлены как содержимое, то есть в виде тега <img src='https://example.com/img.jpg'/>.
Base64 и svg изображения не поддерживаются. Если вы описываете базу знаний в Google Документе, то добавляйте изображения как содержимое, а не ссылку на него.

При создании ответа используется первое изображение из фрагмента статьи. Если статья разделена на секции с заголовками (например, h1, h2, h3), то для каждого заголовка можно использовать отдельное изображение. Викибот не отправляет одно и то же изображение дважды в одном чате.
Для Google Документов использование изображений включено по умолчанию. Если у вас уже был добавлен источник данных и изображения не отправляются, попробуйте добавить его заново. Если вы хотите включить использование изображений для собственной базы знаний, пожалуйста, свяжитесь с нами.
Добавление файла
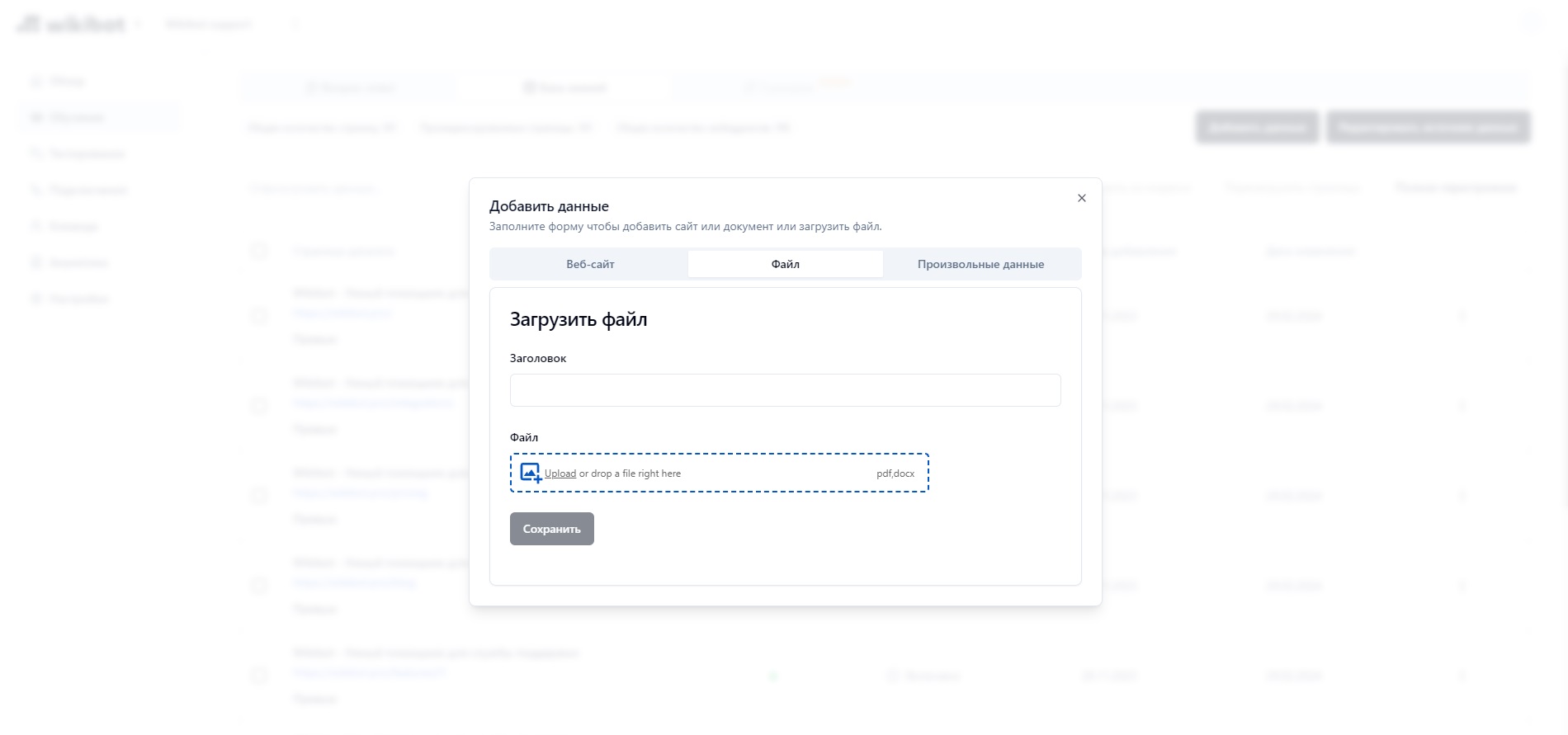
Добавление текстовых данных из файла. На данный момент поддерживаются форматы pdf и docx.
Для лучшей индексации docx для всех смысловых заголовков в вашем тексте рекомендуется использовать стили Заголовок 1, Заголовок 2, Заголовок 3 (Heading 1, Heading 2, Heading 3).
После добавления файла он будет автоматически проиндексирован.
Максимальный размер файла - 10 МБ.
Для каждого типа файлов автоматически создается один источник данных:
- DOCX
Добавление произвольных данных
Укажите заголовок и произвольные текстовые данные, нажмите добавить. Данные будут автоматически добавлены в индекс бота. Также автоматически будет создан источник данных - PRIVATEDATA.
Работа с индексом
Индекс представляет собой набор всех данных, доступных боту для генерации ответа.
Удаление отдельных веб-страниц из индекса невозможно, так как они будут перекачены при следующей перезагрузке веб-сайта. Если какая-то страница является нежелательной, то её можно исключить из индекса. Для этого установите галочку напротив этой страницы и нажмите Удалить из индекса. Добавить в индекс вернет удаленные страницы обратно в индекс.
Вы можете перезагрузить отдельные веб-страницы, если внесли в них какие-то изменения. Для этого поставьте галочки напротив нужных страниц и нажмите Перезагрузить страницы.
Работа со страницами
Справа от каждой загруженной страницы есть меню, через которое можно добавить дополнительный контент для лучшего поиска страницы, а также сгенерировать вопросы и ответы для Первой линии.
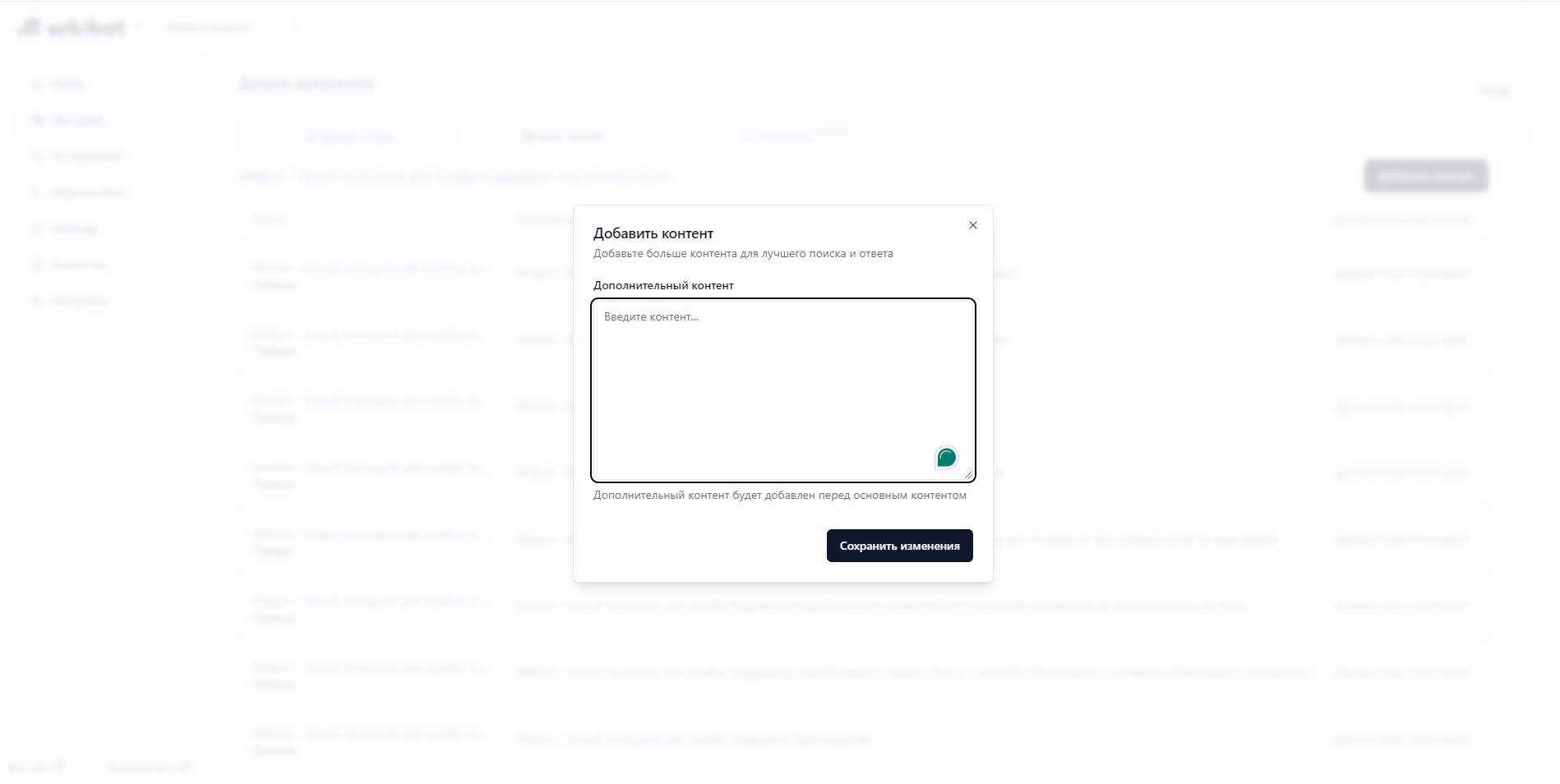
Дополнительный контент
Дополнительный контент добавляется в начало каждого фрагмента и позволяет точнее находить статью по время генерации ответа.
Для этого нажмите кнопку Добавить контент в выпадающем меню напротив каждого документа.
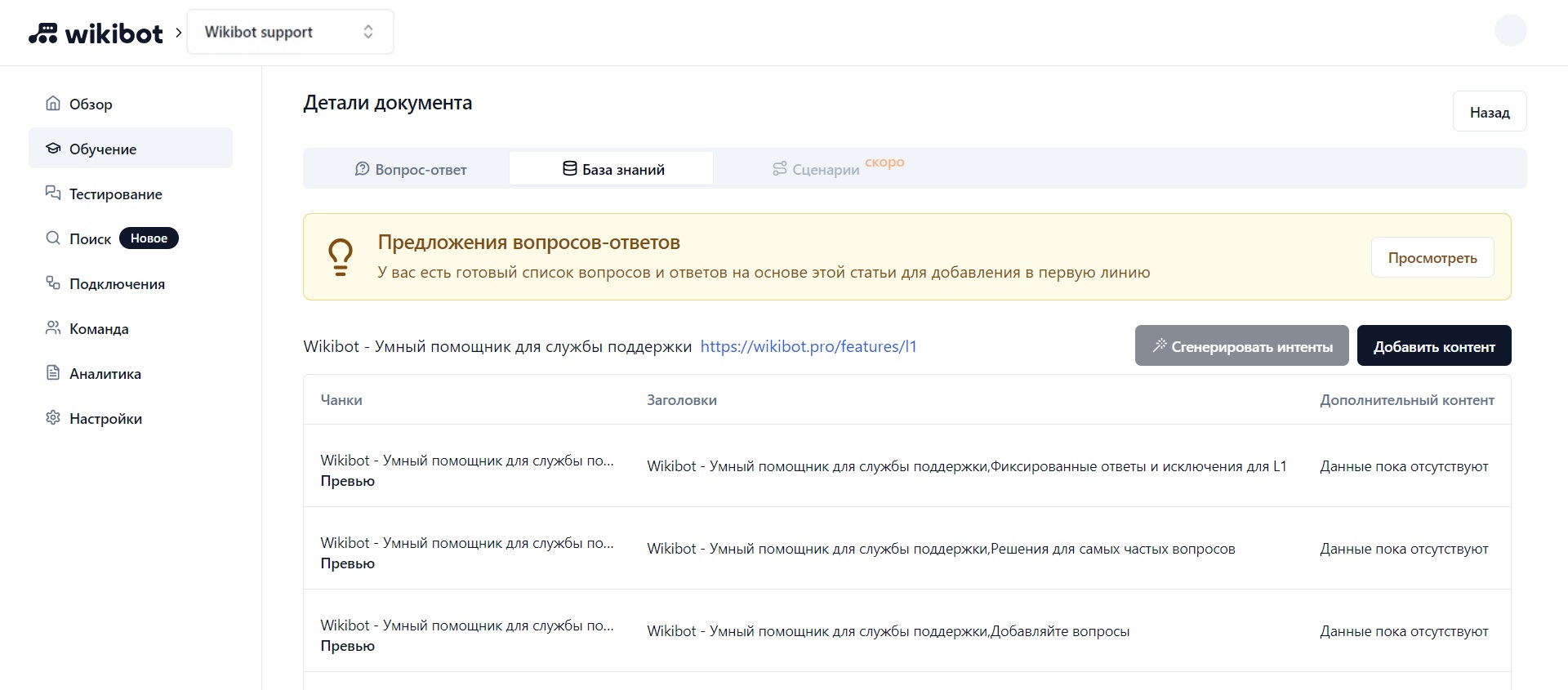
Генерация вопросов и ответов
Вы можете сгенерировать вопросы и ответы для Первой линии на основе содержимого страницы. Для этого на странице просмотра нажмите Сгенерировать интенты.
В зависимости от содержимого страницы будет сгенерировано до 10 вопросов и ответов. Стоимость такой генерации составляет 1 кредит.
Во время процесса генерации будет показан желтый баннер загрузки. По завершении процесса на этом баннере появится кнопка Просмотреть, которая перенаправит вас на страницу с итоговым списком вопросов и ответов, где вы сможете добавить их в Первую линию.
Управление источниками данных
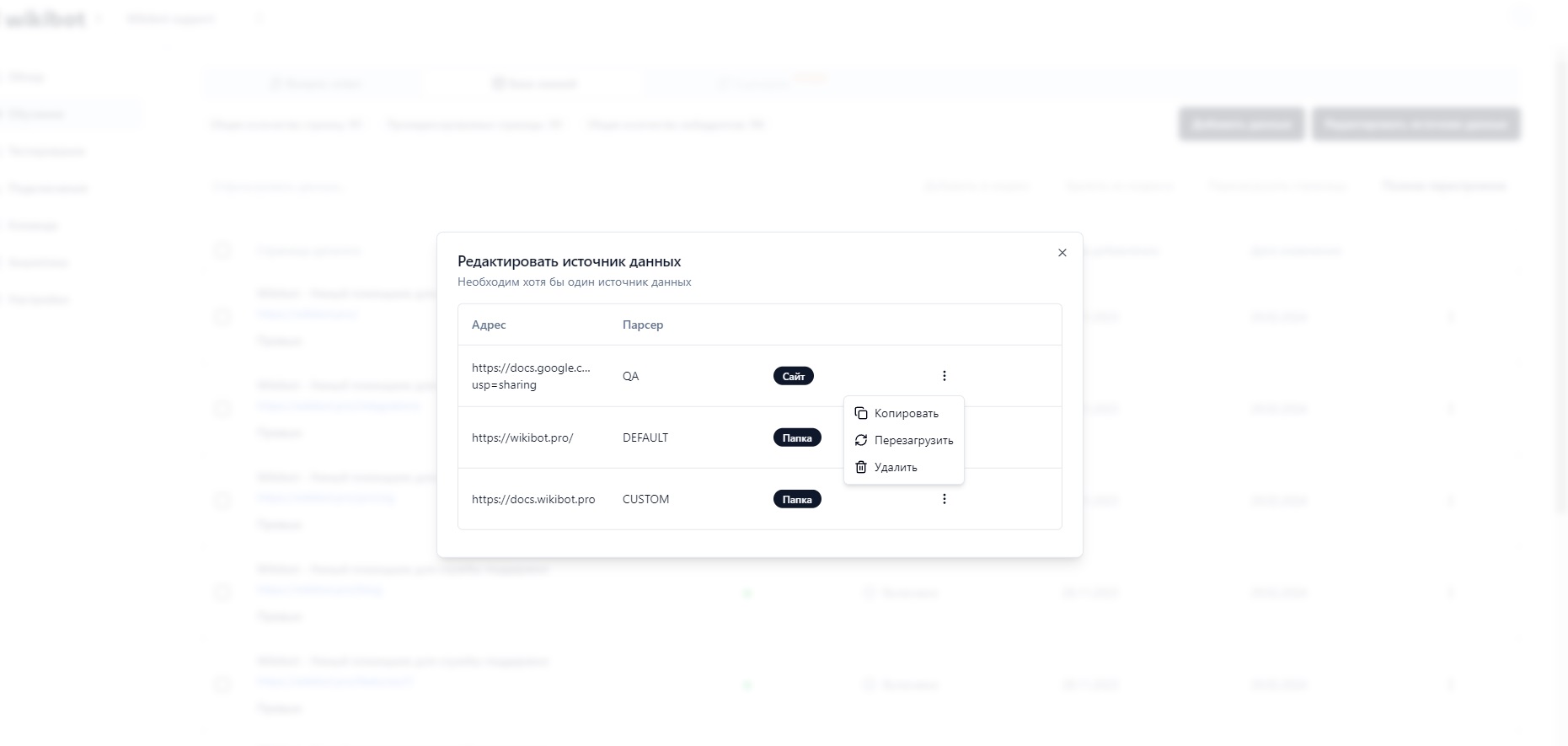
Нажмите Редактировать источники данных, чтобы посмотреть все подключенные источники данных.
В этом окне вы можете удалить, перезагрузить, установить приватность или скопировать источник данных.
Бот не добавляет ссылки на статьи из приватного источника.
Удаление источника данных удалит все связанные с ним страницы данных из индекса. Например, удаление источника данных PDF удалит все загруженные файлы формата pdf.